








In this article I’d like to share the original paper related to the concept of #Transformers in #NLP for #AI #DeepLearning. It is fundamental to the creation of #BERT and #XLNet NLP algorithms, two of the most popular and advanced NLP algorithms that give very good results on different text NLP related tasks. Once you understand transformers, BERT and XLNet are easy to understand. This is one of the easier NLP/Deep Learning papers.
https://arxiv.org/pdf/1706.03762
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
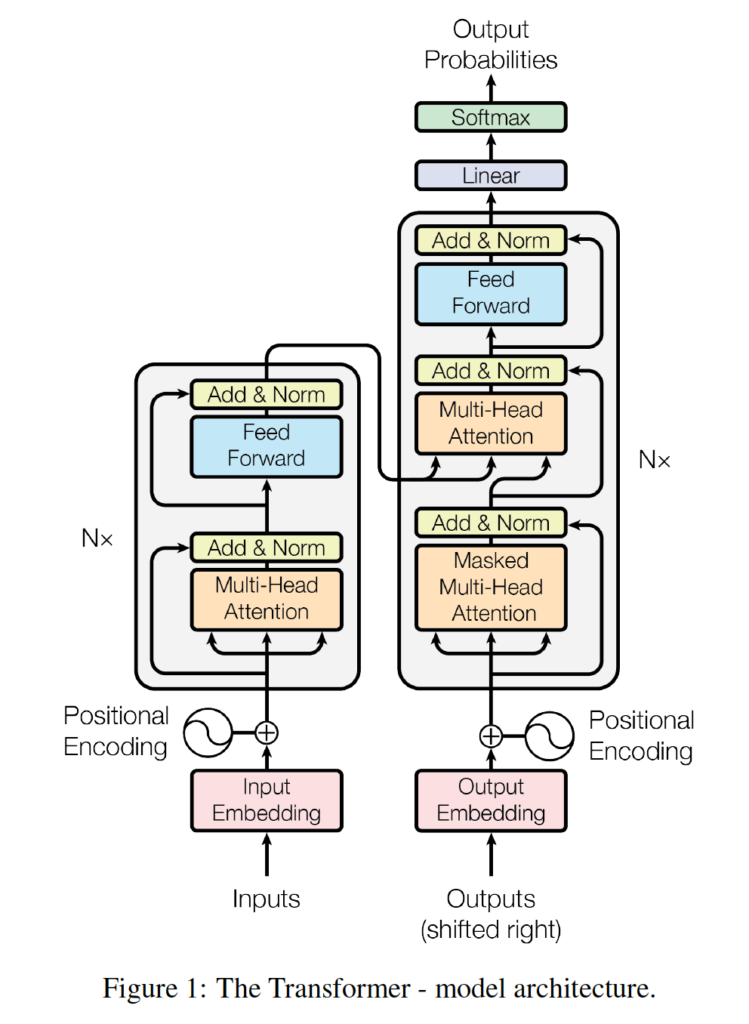
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train.
There are lots of blog posts which explain transformers, BERT and XLNet in a simple way.
You can also look at the examples given in #tensorflow library,widely used for AI/Deep Learning NLP tasks, to learn how to build NLP algorithms for #sentiment analysis, topic modelling, etc using BERT.
https://www.tensorflow.org/text/tutorials/classify_text_with_bert





